|
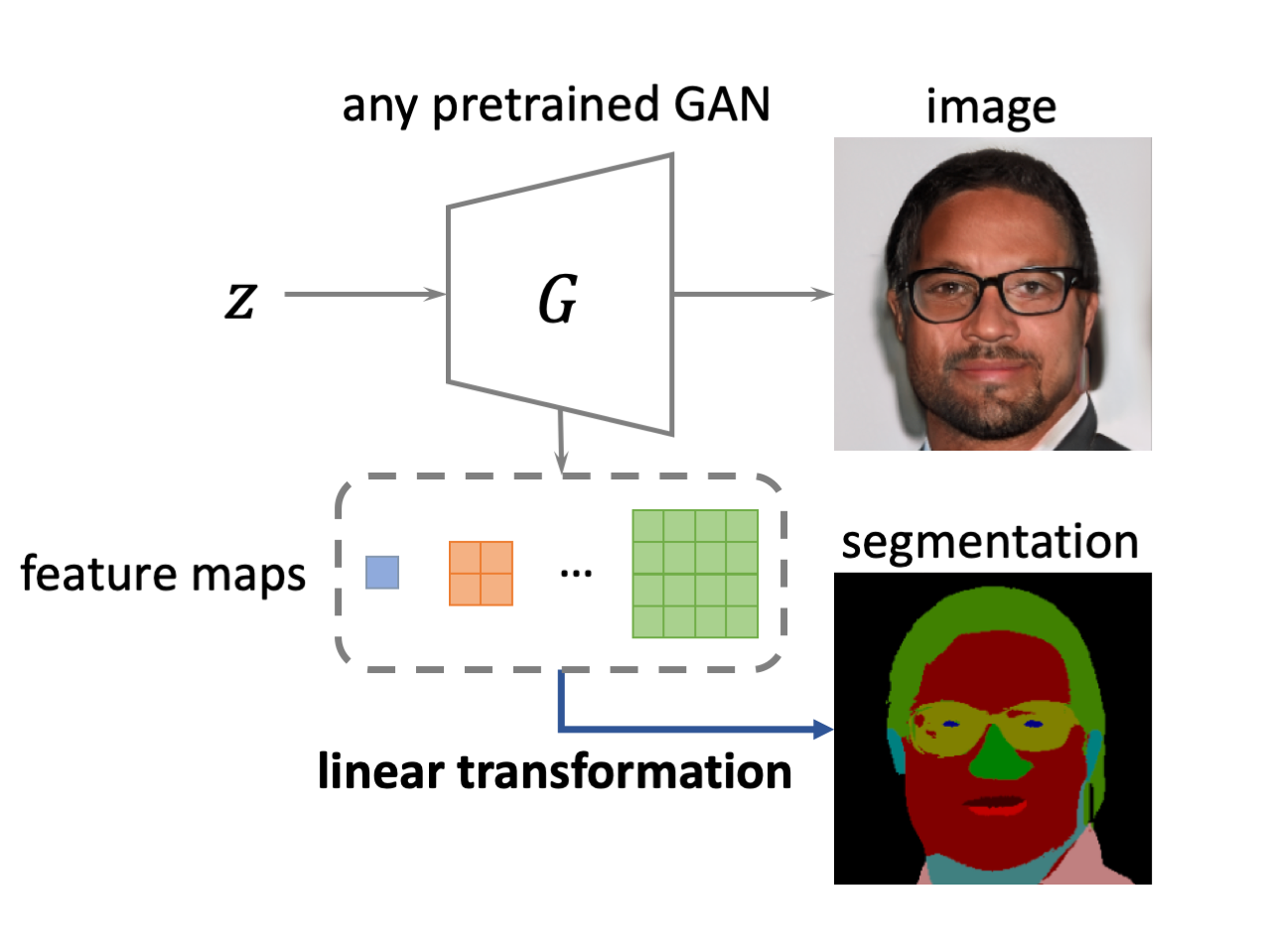
| We find that the generated image semantics can be extracted from GAN's feature maps using a linear transformation. |
|
|
|
|
|
|
|
|
|
|
|
| We find that the generated image semantics can be extracted from GAN's feature maps using a linear transformation. |
| Generative Adversarial Networks (GANs) are able to generate high-quality images, but it remains difficult to explicitly specify the semantics of synthesized images. In this work, we aim to better understand the semantic representation of GANs, and thereby enable semantic control in GAN's generation process. Interestingly, we find that a well-trained GAN encodes image semantics in its internal feature maps in a surprisingly simple way: a linear transformation of feature maps suffices to extract the generated image semantics. |
|
To verify this simplicity, we conduct extensive experiments on various GANs and datasets; and thanks to this simplicity, we are able to learn a semantic segmentation model for a trained GAN from a small number (e.g., 8) of labeled images. Last but not least, leveraging our findings, we propose two few-shot image editing approaches, namely Semantic-Conditional Sampling and Semantic Image Editing. Given a trained GAN and as few as eight semantic annotations, the user is able to generate diverse images subject to a user-provided semantic layout, and control the synthesized image semantics. |
 |
Jianjin Xu, Changxi Zheng Linear Semantics in Generative Adversarial Networks In CVPR 2021. (hosted on ArXiv) [Bibtex] |

|
|
Linear Semantic Extractor (LSE). We find that the generated image semantics can be extracted from GAN's feature maps using a linear transformation. As shown in the figure above, the LSE simply upsamples and concatenates GAN's feature maps into a block, and then run a 1x1 convolution on top of the block. The LSE is trained using cross-entropy loss using supervisions provided by off-the-shelf segmentation network. We conduct extensive experiments to support the linear semantics hypothesis. Our evidence is two-fold. |

|
|
Evidence 1: LSE suffices to extract the semantics from GANs. We study to what extent could the semantics be better extracted by Nonlinear Semantic Extractors (NSEs). Table.1 shows that in most cases, the performance of LSE is within a range of 3.5% relative to the best NSE method. Although NSEs achieve the best performance, their differences with the LSEs are marginal. This experiment directly supports that LSE suffices to extract GAN's semantics. |
|
|
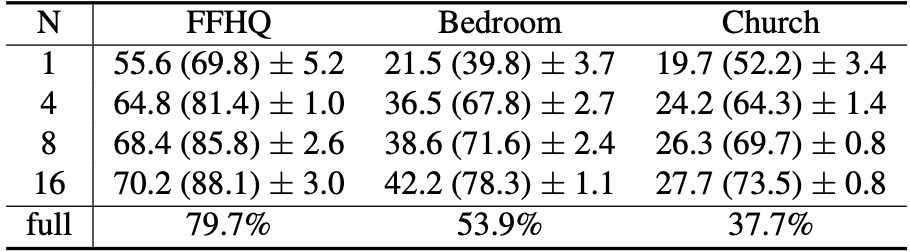
Evidence 2: LSE can be trained using few annotations. We only use N=1, 4, 8, 16 annotations to train the LSE (for StyleGAN2 models) and repeatedly train each LSE 5 times to account for the training data variance. As shown in Table.2, given N=16 annotations, the 16-shot LSEs achieve around 90%, 80%, and 70% performance relative to the fully trained models. |

|

|

|
|
Figure: qualitative comparison of LSE, NSE-1, and NSE-2. |
|
Video: demonstration of training a few-shot LSE. |
|
After annotating a few annotations, we obtain a competitve semantic segmentation model for GAN generated images. The few-shot LSEs further enables image editing applications. |
|
We propose two image editing applications: few-shot Semantic Image Editing and few-shot Semantic Conditional Sampling. Both applications are formulated as an optimization problem: find a latent vector that produces images satisfying given semantic constraints. For SIE, we optimize the initial latent vector to get close to the user-modified semantic mask. For SCS, we optimize several random latent vectors and return the closest one to the user-specific semantic mask. |

|
|
Figure: comparison of color-based editing, SIE using UNet (baseline), SIE using 8-shot LSE (ours), and SIE using fully trained LSE. |
|
Semantic Image Editing. In many cases, the user may want to control a GAN’s image generation process. For example, they might want to adjust the hair color of a generated facial image from blond to red; and the user may draw a red stroke on the hair to easily specify their intent. However, without explicit notion of semantics, the minimization process may not respect image semantics, leading to undesired changes of shapes and textures. Leveraging LSE, we propose an approached called Semantic Image Editing (SIE) to enable semantic-aware image generation. Our method can edit the images better than the baseline, SIE(UNet). More results are shown in the video below. |
|
|
|
Video: more Semantic Image Editing results using our web application.
|
|
Semantic Conditional Sampling (SCS) aims to synthesize an image subject to a semantic mask. The baseline for SCS is to use a pretrained segmentation network. The proposed method is to use few-shot LSEs. The comparisons are shown below. |

|

|
| SCS on FFHQ using UNet (baseline). | SCS on Church using DeepLabV3 (baseline). |

|

|
| SCS on FFHQ using 8-shot LSE (ours). | SCS on Church using 8-shot LSE (ours). |
Acknowledgements |